Are more humanlike models also smarter? My research on VLMs.
Adapted from my MSc thesis and a talk I gave at DataFest Tbilisi 2024.
Recent AI advances have included the development of vision-language models, or VLMs. These multimodal models seem miles ahead of their text-based LLM peers, having both a visual and linguistic “understanding” of the world. But the debate over their capabilities has only intensified. AI researchers keep asking: What does the model know, and how does it know it?
There are, broadly speaking, two ways to get at this line of questioning.

The author presenting this material at Utrecht University.
The first focuses only on the “what”: this is the land of benchmarks. This approach relies on creating especially challenging questions for a model to solve; if the model can answer these correctly, researchers might conclude that it knows something, or at least possesses competence that emulates knowledge.
The second focuses on the “how”: it’s interested not just in whether a model can answer the questions correctly, but in whether the method the model uses to arrive at its answer somehow makes sense. But makes sense to whom? This is where the concept of humanlikeness enters the picture.
Historically, humanlikeness pretty much was the standard by which the quality of AI systems was measured. In the 1970s, AI pioneer Marvin Minsky famously said: “I draw no boundary between a theory of human thinking and a scheme for making an intelligent machine”1 . But today, it is an object of some dispute whether and how much humanlikeness matters. After all, there are highly successful AI systems that achieve their goals in ways that seem inhuman, relying on “spurious” correlations or other workarounds that humans would not or could not use. (A famous example is a model ‘incorrectly’ using background data to distinguish images of huskies and wolves.2) But since these models can still work quite well, should we still see models that work like human brains as superior?
My thesis project
The question I asked in my thesis was simple: if we take several leading open-source VLMs, do those that process their inputs in a more humanlike way do better? I expected that the answer would be “yes”: the more similar a model is to human minds, the better it performs on the challenge.
The “do better” part is easy to measure: I take an existing benchmark (VALSE3) where models are asked to distinguish the correct from the incorrect caption for a series of images. Here is an example stimulus:

An example stimulus from the VALSE benchmark.
Models that are better at choosing the correct caption are said to perform better.
The “humanlikeness” part turns out to be more difficult to measure. The method I came up with to measure how humanlike the models are rests on saliency, i.e. what parts of the input models pay attention to. This is only one dimension of humanlikeness, but it’s a useful one, and variants of this approach have been used in prior research.
What models and people pay attention to
To find out whether models are humanlike in this way, we need to 1) measure what models are paying attention to, and 2) measure what humans are paying attention to.
Model saliency
To figure out where a model is “looking”, I used the well-established SHAP method, which involves segmenting the image and then starting to delete different parts of the image. The parts whose deletion makes the biggest impact on the model’s output are more “important” to the model, i.e. the model is paying more attention to them. Each region of the image gets a score based on how different the model’s output is when that region is included vs. when it is not included, generating a Shapley value:
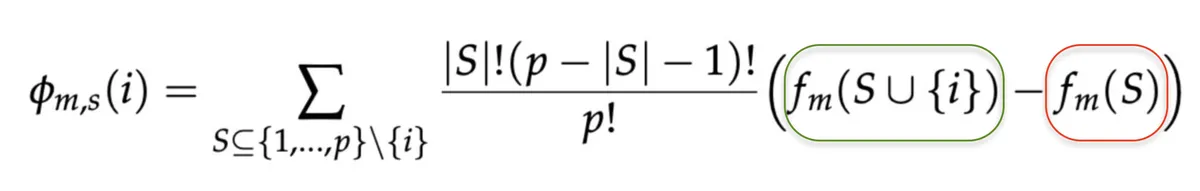
For the image above, we segment it into 16 squares, then run various versions of the image through the CLIP model, and see which squares affect the output score the most.
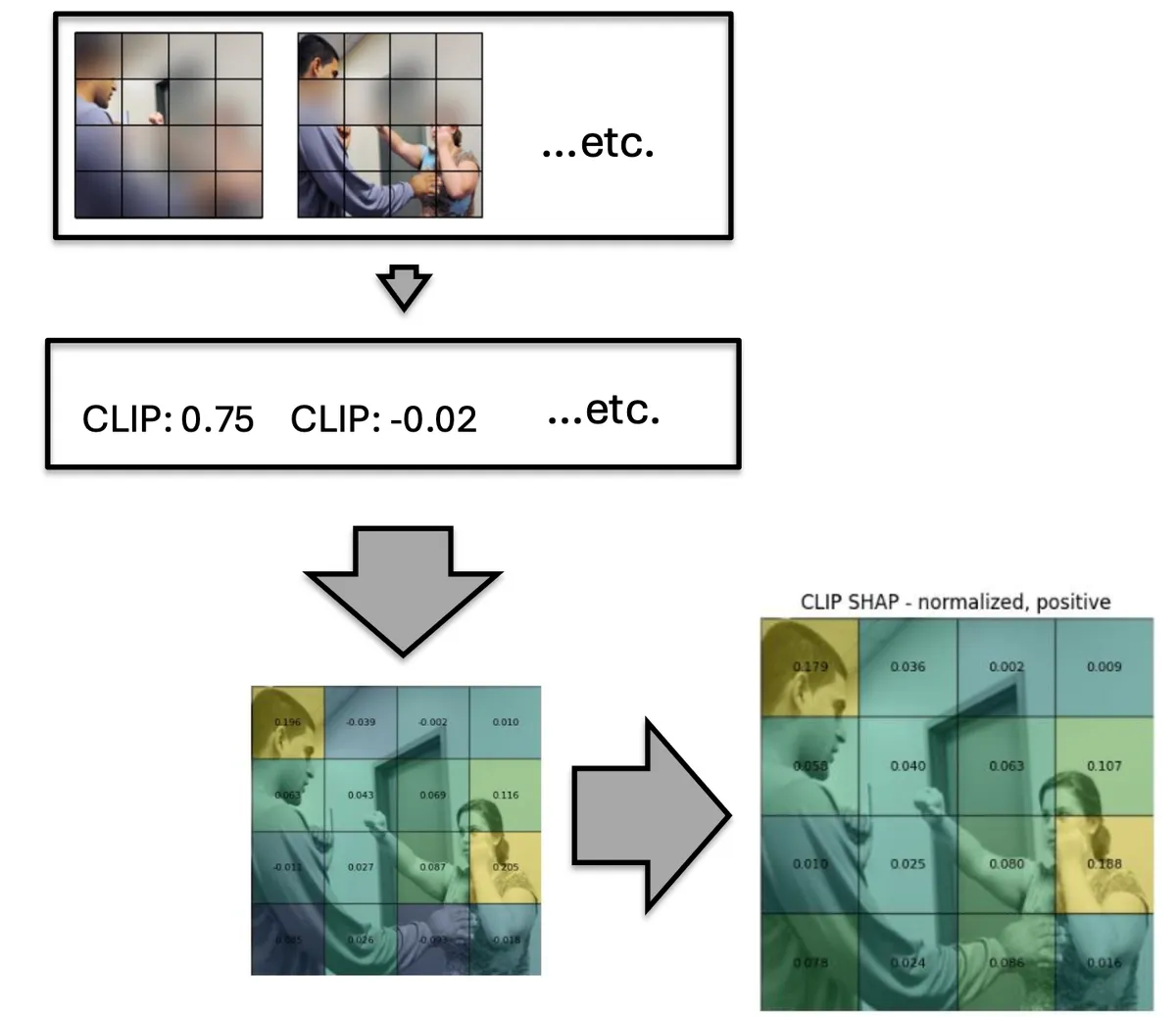
How I generated the VLM saliency maps.
Human saliency
To figure out where humans are looking, I created an online experimental environment. Subjects recruited through Prolific were asked to choose the correct caption for a blurred image. To see more detail, they could click around on the blurred image, unblurring those areas. This method, inspired by a previous study4, gives an interactive, task-oriented way to approximate what parts of an image capture the attention of a human who is attempting to choose the correct caption.
I then then converted a representation of the human’s clicks into an attention map, averaging multiple people’s attention into an aggregate human saliency map.
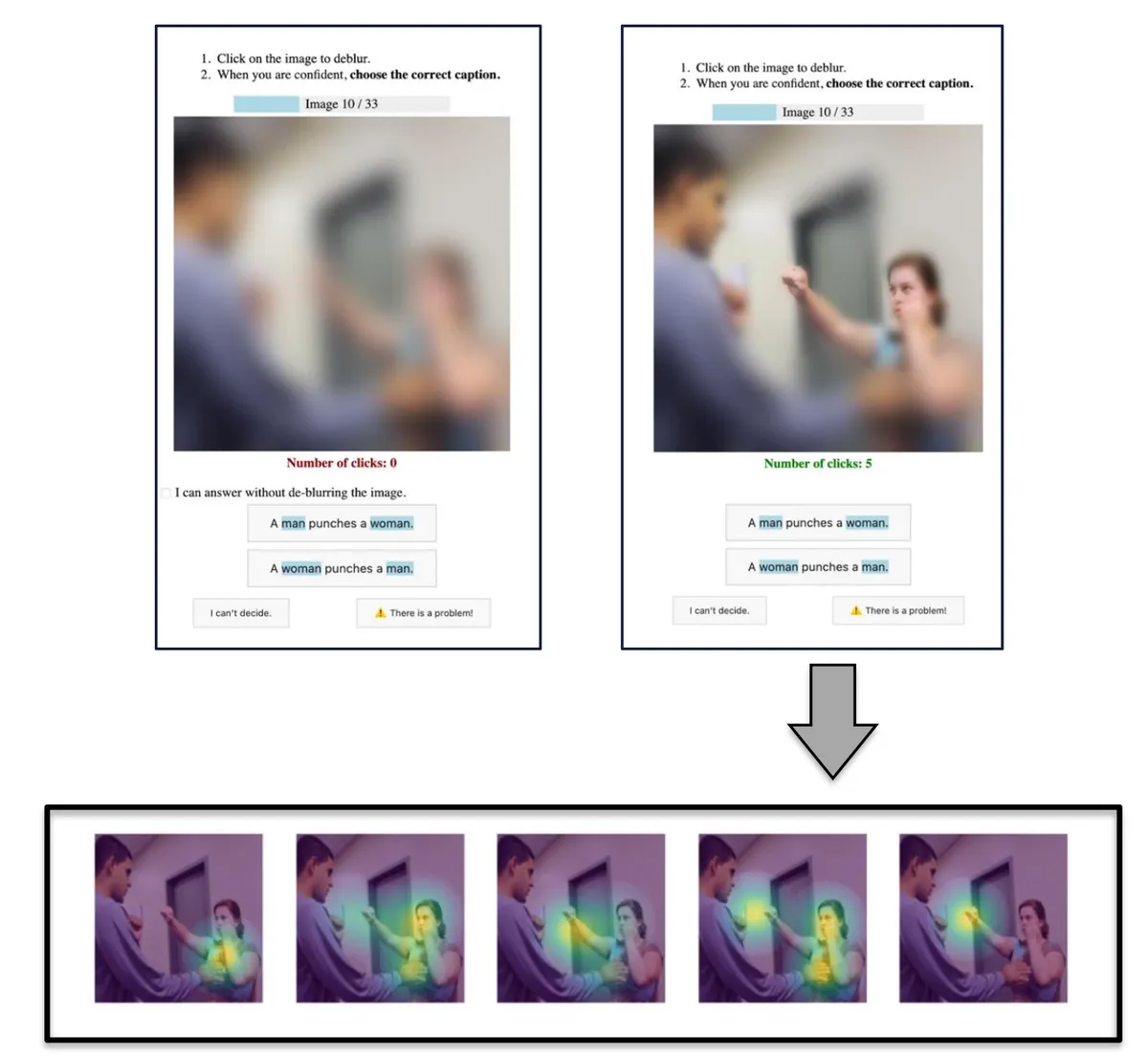
How I generated the human saliency maps.
So do more humanlike models do better?
First, on average, there is a positive correlation between the human and model saliencies: on average, models and people pay attention to similar things in the image. That makes sense, since the information obviously needed to answer the question is located in specific spots. This is good news for the project because it means the human-machine similarity we are trying to measure is real, and that the models are really focusing on areas of the image that make intuitive sense to people.
But both within each model and across models, there is no statistically significant relationship (much less a positive one) between model accuracy and humanlikeness.
Comparison across models
Better and worse models are equally similar to humans in terms of where in the image they pay attention.
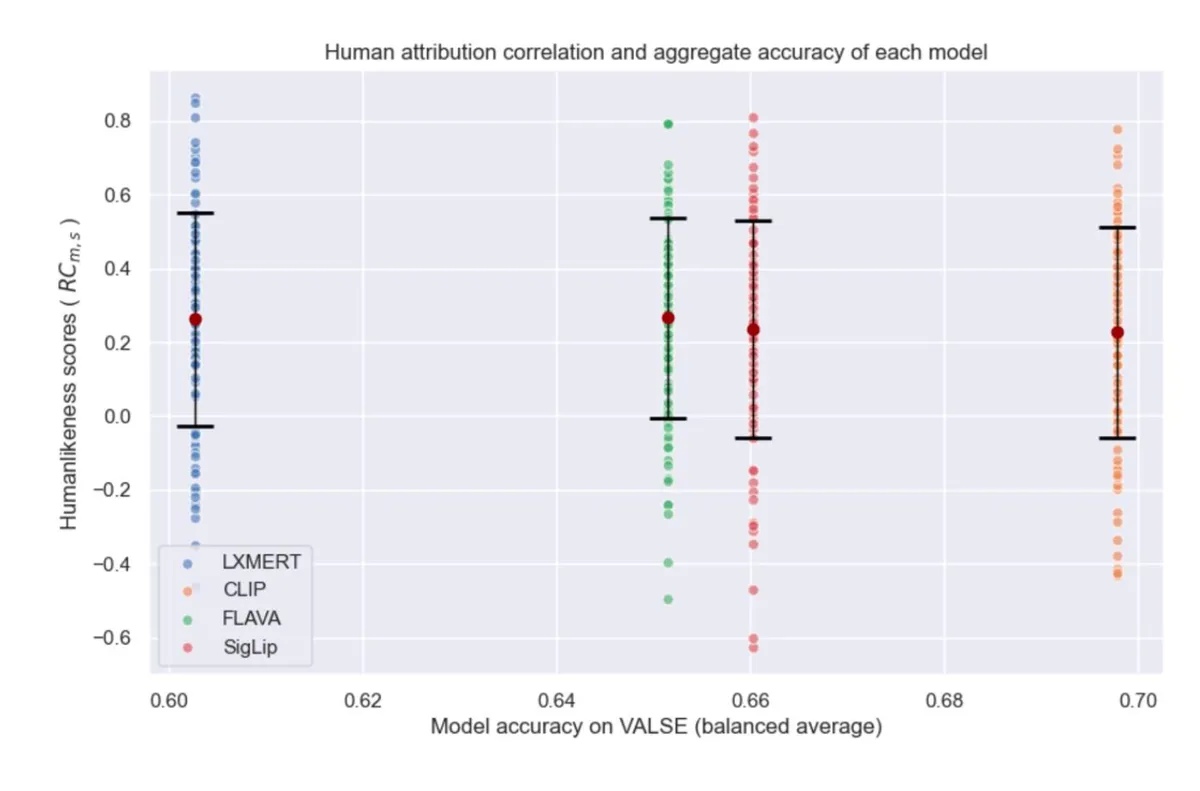
Models which differ by their average performance on the VALSE benchmark do not significantly differ by average saliency humanlikeness.
Comparison within models
If we take each model separately and look at how it does from image to image, we also see that there is no significant relationship between a model’s accuracy and confidence on an image and how “humanlike” its attention was for that image. You can see these non-significant relationships in these scatterplots:
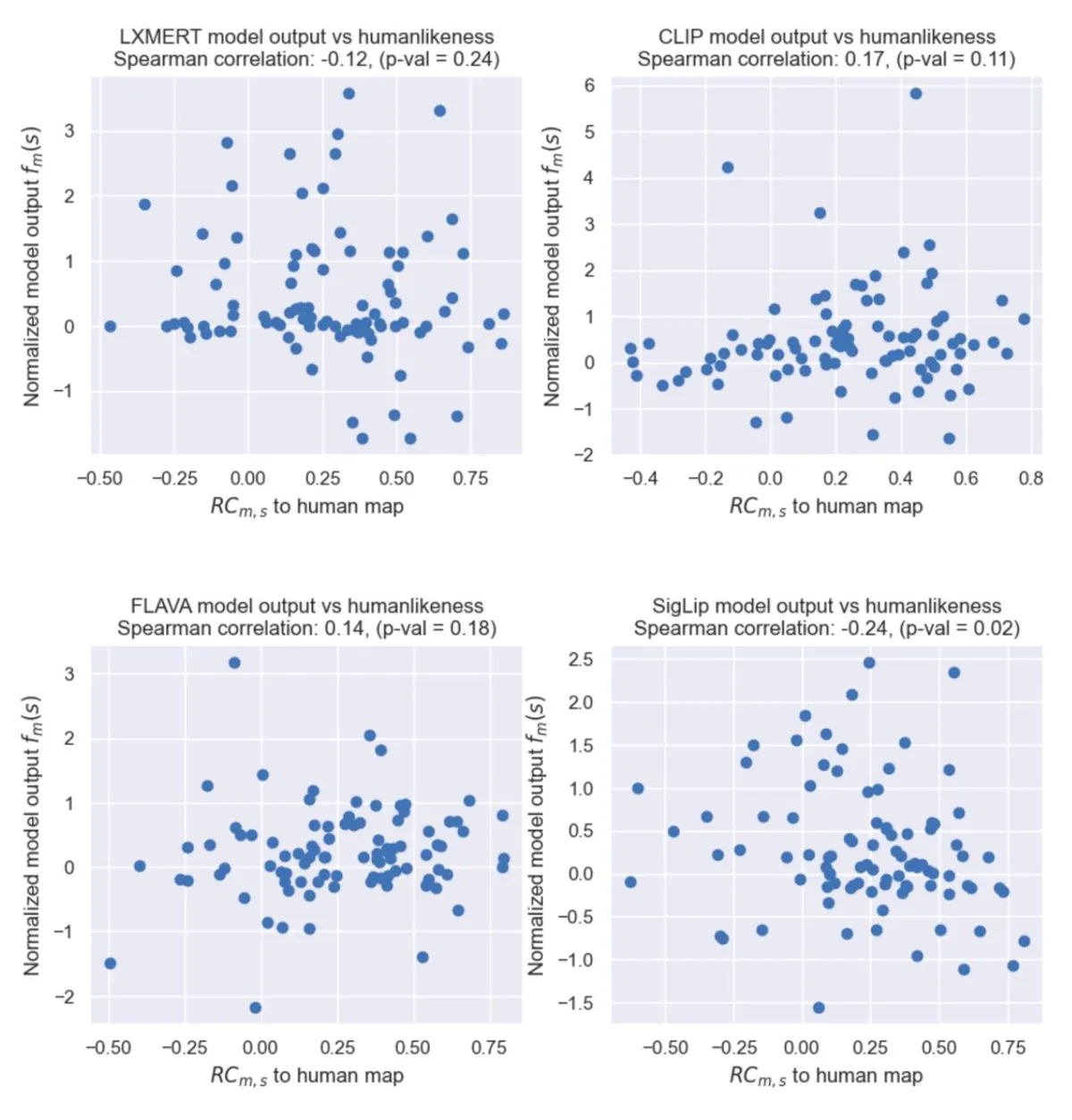
For each model, images where it does better or worse are not significantly different in terms of how humanlike the model's saliency was.
Closing thoughts
So at least for this one type of humanlikeness for this type of model, "more human" and "smarter" are not statistically related. If this replicates across domains, models, and datasets, it undermines the case of those who hold up humanlike cognition as the gold standard.
Even so, there are reasons other than performance that we might still favor humanlike intelligences. For instance, AI systems that seem to resemble human minds more might be seen as more trustworthy. If nothing else, their decisions are more persuasive. Performance is not the only thing you can optimize for.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. “‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier.” arXiv. https://doi.org/10.48550/arXiv.1602.04938.↩
Lake, Brenden M., Tomer D. Ullman, Joshua B. Tenenbaum, and Samuel J. Gershman. 2016. “Building Machines That Learn and Think Like People.” arXiv.Org. April 1, 2016. https://arxiv.org/abs/1604.00289v3.↩
Parcalabescu, Letitia, Michele Cafagna, Lilitta Muradjan, Anette Frank, Iacer Calixto, and Albert Gatt. 2022. “VALSE: A Task-Independent Benchmark for Vision and Language Models Centered on Linguistic Phenomena.” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 8253–80. https://doi.org/10.18653/v1/2022.acl-long.567.↩
Das, Abhishek, Harsh Agrawal, C. Lawrence Zitnick, Devi Parikh, and Dhruv Batra. 2016. “Human Attention in Visual Question Answering: Do Humans and Deep Networks Look at the Same Regions?” arXiv.Org. June 11, 2016. https://arxiv.org/abs/1606.03556v2.↩